Die Chancen und Möglichkeiten, die das „Internet of Things“ bietet, zu erkennen und für sich zu nutzen, ist es für jedes Unternehmen – unabhängig von der Branche oder der Größe – heutzutage besonders wichtig, um wettbewerbsfähig zu bleiben und langfristig erfolgreich zu sein. Denn durch die Integration von IoT Technik in Geschäftsprozesse und Produkte können Unternehmen ihre Betriebsabläufe effizienter gestalten, Kosten senken, bessere Entscheidungen treffen, innovativere Produkte anbieten und neue Einnahmequellen erschließen. Unternehmen, die auf den Einsatz von IoT Technik – aus welchem Grund auch immer (Know-how, Manpower, etc.) – verzichten, laufen große Gefahr, Kostennachteile zu erleiden, Umsätze einzubüßen und Marktanteile zu verlieren.
Beim Internet der Dinge (IoT) besteht das Grundprinzip in der Vernetzung von physischen Geräten und Objekten, die mit Sensoren, Software und Netzwerkverbindungen ausgestattet sind, um Daten zu sammeln, zu analysieren und zu kommunizieren. Eine der größten Herausforderung beim Einsatz von IoT Technik ist dabei die Menge der von den Sensoren gesammelten Daten, die verarbeitet, analysiert und ausgewertet werden müssen. In vielen IoT Szenarios ist es wichtig, dass das sehr zeitnah geschieht, im Idealfall in Echtzeit, um schnelle Entscheidungen zu ermöglichen und davon abhängige Aktionen automatisiert auslösen zu lassen. Eine Lösung für dieses Problem stellt das sogenannte „Edge Computing“ dar.
Edge Computing
Beim Edge Computing findet direkt auf den IoT Devices, also sozusagen „am Rand“ (engl. „Edge“) des Netzwerkes, eine Vorverarbeitung der gesammelten Daten statt, um so die Menge der in die Cloud zu übertragenden Daten zu minimieren und damit sowohl die Latenzzeiten als auch die Kosten für die Datenübertragung und die Speicherung in der Cloud zu reduzieren. Es kann auf verschiedenen Ebenen stattfinden, wie zum Beispiel auf der Ebene von Endgeräten, Netzwerkknoten oder Gateway-Geräten. Edge Computing ist eine wichtige Ergänzung zur Cloud-Computing-Architektur und wird zunehmend von Unternehmen und Organisationen genutzt, um die Skalierbarkeit und Effizienz ihrer IT-Infrastruktur zu verbessern.
Aber wäre es eigentlich nicht besser, wenn die zur Auswertung und Analyse notwendige Übertragung der Daten in die Cloud ganz wegfallen könnte und die Datenverarbeitung komplett auf dem IoT Device direkt stattfindet? Wenn die IoT Devices also selber Entscheidungen treffen und Aktionen autonom auslösen könnten? Wenn sie also in gewisser Weise „intelligent“ wären? Dank der aktuellen rasanten Entwicklungen im Bereich der Künstlichen Intelligenz ist genau das bereits tatsächlich schon möglich. Wenn KI auf IoT trifft, wird das als „AIoT“ bezeichnet.
AIoT: Artificial Intelligence of Things
AIoT steht für „Artificial Intelligence of Things“ und bezieht sich auf die Integration von künstlicher Intelligenz (engl.: Artificial Intelligence, kurz „AI“) in das Internet der Dinge (engl.: Internet of Things, kurz „IoT“). Bei AIoT handelt es sich um die nächste Stufe des IoT, denn der Einsatz von KI Technologie in IoT Projekten eröffnet neue, ungeahnte Möglichkeiten bei der Vernetzung und Automatisierung von Maschinen und Prozessen. Die KI gestützte Analyse und Auswertung der Daten direkt auf den IoT Devices ermöglicht es, dass Entscheidungen von den Geräten autonom getroffen werden können, um dann je nach IoT Anwendungsszenario die vorgesehenen Aktionen auszulösen. So wird Dank KI beispielsweise aus einem „normalen“ IoT Sensor ein „smarter“ IoT Sensor.
Smarte AIoT Sensoren
Smarte IoT Sensoren sind hochentwickelte Messgeräte, die nicht nur eine Messgröße erfassen, sondern auch in der Lage sind, mit Hilfe von Künstlicher Intelligenz (KI) und Algorithmen diese Messdaten zu verarbeiten, zu analysieren und autonom entsprechende Aktionen auszulösen. Sie sind in der Regel mit Mikroprozessoren, Speichern, Kommunikations- und Energieversorgungssystemen ausgestattet, was eine Verarbeitung der vom Sensor erfassten Daten direkt beim Sensor ermöglicht. Doch wie wird aus einem „normalen“ IoT Sensor ein „smarter“ AIoT Sensor? Woher bekommt ein smarter AIoT Sensor seine Intelligenz, um autonom Entscheidungen treffen und Aktionen auslösen zu können? Die Antwort: Durch entsprechende Software und Firmware, die direkt in die Sensor-Hardware eingebettet wird, und daher als „Embedded“ bezeichnet wird. Um solche KI gestützten Embedded Software Lösungen für Smarte AIoT Sensoren zu erstellen, gibt es spezielle Toolkits auf dem Markt. Eines dieser KI Toolkits, welches unsere Spezialisten in der IoT Manufaktur für Embedded Lösungen gerne in ihren AIoT Projekten einsetzen, ist „SensiML“.
Was ist SensiML?
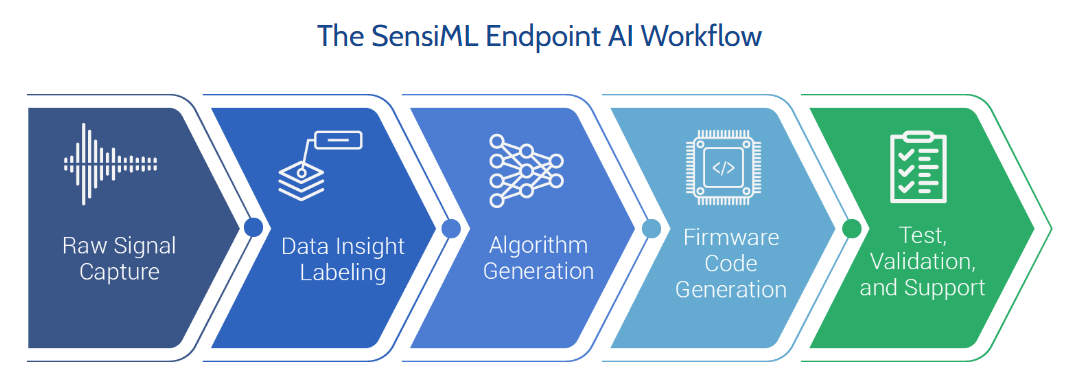
SensiML ist eine Plattform für maschinelles Lernen (ML) und Entwicklung von Edge-KI-Lösungen für das Internet der Dinge (IoT), die von der Datenvorbereitung bis zur Implementierung der Modelle auf Geräten reicht und damit Echtzeit-Ereigniserkennung und Inferenz an den IoT-Sensor-Endpunkt bringt. SensiML bietet hochmoderne AutoML-Softwaretools, die Firmware- und Data-Science-Know-how vereinen, darunter automatisierte Modellgenerierung, Modellvalidierung, Modellverwaltung und eine Bibliothek mit vorgefertigten ML-Algorithmen. Damit versetzt SensiML Anwendungsentwickler in die Lage, schnell intelligente IoT-Geräte zu entwickeln, die rohe Sensordaten autonom in aussagekräftige Erkenntnisse verwandeln und vordefinierte Aktionen auslösen. Die Lösung ist Hardware-, JVM- und Betriebssystem-unabhängig und optimiert für den Einsatz in Embedded Edge-Plattformen wie Gateways und Hub-Geräten. Dabei läuft sie auf mehr als 40 verschiedenen Arten von Gateways und ist für viele JVMs, Betriebssysteme und Hardwarekonfigurationen portiert und optimiert. Da die intelligente Kompilierung von SensiML für MCU, Digitalen Signalprozessor (DSP) und Field-Programmable Gate Array (FPGA) optimiert ist, können Hardware-Ressourcen maximal ausgenutzt werden.
Das SensiML Toolkit ermöglicht eine schnelle und effiziente Entwicklung von IoT Edge-Computing-Lösungen für die verschiedensten Anwendungsbereiche, von der Industrieautomatisierung (Industrie 4.0) über Wearables und Smart-Home-Systeme bis hin zu medizinischen Geräten. Es wird von unseren IoT-Spezialisten gerne für das Rapid Prototyping von KI-gestützten, sensorbasierten IoT-Lösungen eingesetzt, denn insbesondere die AutoML-Funktionen von SensiML erleichtern und beschleunigen die Entwicklungsprozesse von Sensor basierten Embedded Software Systemen erheblich und ermöglichen damit entsprechend auch die schnellere Durchführung von Proof-of-Concepts für KI basierte IoT-Lösungen.
Wie funktioniert SensiML?
Die Vorteile für den Einsatz von SensiML ergeben sich aus den automatisierten Methoden des maschinellen Lernens, die die Plattform verwendet, um die Daten von den IoT Sensoren zu analysieren und Modelle für die Erkennung von Ereignissen zu erstellen. Die Funktionsweise von SensiML lässt sich in mehrere Schritte gliedern. Zunächst müssen die Daten von IoT Sensoren erfasst werden. Dies können zum Beispiel Beschleunigungssensoren oder Temperatursensoren sein, je nach Anwendungsfall. Anschließend werden die erfassten Daten bereinigt und vorverarbeitet, um Rauschen zu reduzieren und die Datenqualität zu verbessern. SensiML extrahiert automatisch Merkmale aus den vorverarbeiteten Daten, um sie für das maschinelle Lernen geeignet zu machen. Anschließend nutzt SensiML automatisierte Methoden des maschinellen Lernens, um Modelle für die Erkennung von Ereignissen zu erstellen. Hierbei werden verschiedene Algorithmen verwendet, wie z.B. künstliche neuronale Netze, Entscheidungsbäume oder Random Forests. Die erstellten Modelle werden anschließend validiert und optimiert, um sicherzustellen, dass sie zuverlässig und effektiv sind. Schließlich können die Modelle in IoT-Geräte integriert werden, um Ereignisse zu erkennen und entsprechende Aktionen auszulösen.
Sensor-Hardware für SensiML
SensiML ist ein IoT Toolkit, mit dem es möglich ist, IoT Sensoren relativ schnell und einfach zu „smarten“ – also intelligenten – AIoT Sensoren zu machen. Dies ist in IoT-Projekten besonders für das Rapid-Prototyping und das Proof-of-Concept sehr nützlich. Es gibt bereits eine große Anzahl an IoT Sensor-Hardware, die für den Einsatz von SensiML geeignet ist.
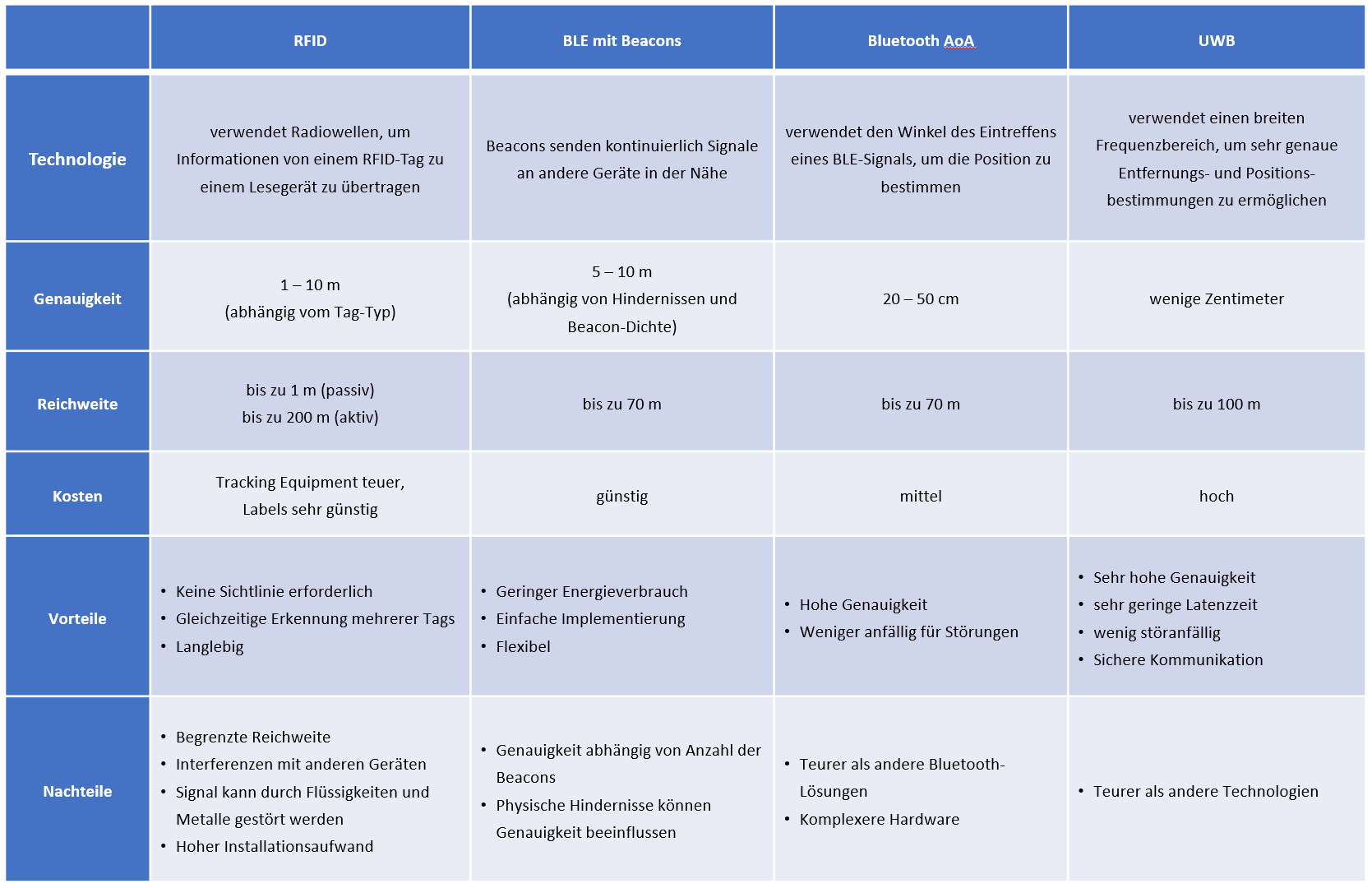
LSM6DSOX
Wenn es darum geht, genaue und zuverlässige Bewegungs- und Orientierungsdaten für Anwendungen zu erfassen, wird von unseren IoT Spezialisten besonders gerne der MEMS-Sensor LSM6DSOX aus der iNEMO-Familie von STMicroelectronics eingesetzt. Denn in diesem Chip arbeitet ein Machine-Learning-Core, der die Bewegungsdaten anhand bekannter Muster klassifiziert und damit den Hauptprozessor von dieser ersten Stufe der Aktivitätsverfolgung entlastet. Damit sinkt nicht nur der Energieverbrauch drastisch, sondern gleichzeitig verbessern sich auch die Erkennung und die Verarbeitungsgeschwindigkeit. Beim LSM6DSOX handelt es sich um ein System-in-Package (SiP) mit einem kombinierten mechanischen 3D-Beschleunigungsmesser und 3D-Gyroskop zusammen mit einem Low-Power-CMOS-ASIC zur Auswertung in einem kleinen Land-Grid-Array-Gehäuse (LGA-14L) aus Kunsstoff. Sein Beschleunigungsbereich von ±2/4/8/16g und der Winkelratenbereich von ±125/250/500/1000/ 2000 dps sind dynamisch wählbar. Der Hochleistungsmodus sorgt für hohe Performance bei nur 0,55 mA Stromverbrauch. Mit seinem extrem rauscharmen Beschleunigungsmesser und Gyroskop kombiniert der Sensor eine Always-on-Benutzererfahrung mit einer hohen Messgenauigkeit. Zum Ausprobieren und für die Prototypenentwicklung bietet ST Plug&Play-fähige Evaluation-Tools, wie z.B. die SensorTile.box an.
Ausführliche Spezifikationen
https://www.st.com/en/mems-and-sensors/lsm6dsox.html
https://docs.zephyrproject.org/3.1.0/boards/arm/sensortile_box/doc/index.html
Konfiguration
https://docs.platformio.org/en/latest/boards/ststm32/steval_mksboxv1.html#sensortile-box
Anleitungs-Video
https://www.youtube.com/watch?v=nGVZ0RN01YU
Use Case Beispiel Video
https://www.youtube.com/watch?v=4jkQ4lLmbno
Arduino Nano33 BLE Sense
Für Freunde des Arduino ist der Arduino Nano33 BLE Sense interessant. Hierbei handelt es sich um eine kompakte und vielseitige Entwicklungsplatine, die auf dem Arduino-Entwicklungsframework basiert und eine Vielzahl von Funktionen und Sensoren bietet. Die Platine verfügt über einen Arm Cortex-M4-Prozessor mit Bluetooth Low Energy (BLE) und einen 9-Achsen-Inertialsensor (Gyroskop, Beschleunigungsmesser und Magnetometer) sowie Umgebungssensoren wie Temperatur-, Luftfeuchtigkeits- und Luftdrucksensor. Darüber hinaus verfügt die Platine über ein Mikrofon, NFC-Tag-Antenne und eine RGB-LED. Der Arduino Nano33 BLE Sense ist auch mit der Arduino-Entwicklungsplattform kompatibel und kann mit der Arduino-IDE programmiert werden.
- Mikrocontroller: Das Board ist mit einem Nordic nRF52840 Mikrocontroller ausgestattet, der eine hohe Rechenleistung und eine geringe Stromaufnahme bietet.
- Sensoren: Der Arduino Nano33 BLE Sense verfügt über eine breite Palette von Sensoren, darunter Beschleunigungsmesser, Gyroskop, Magnetometer, Luftdrucksensor, Temperatursensor, Feuchtigkeitssensor und Mikrofon.
- Konnektivität: Das Board ist mit Bluetooth Low Energy (BLE) ausgestattet, um eine drahtlose Verbindung zu anderen Geräten und Cloud-Plattformen herzustellen.
- Stromversorgung: Das Board kann über eine USB-Verbindung oder eine externe Batterie betrieben werden.
- Entwicklungssoftware: Der Arduino Nano33 BLE Sense ist mit der Arduino-IDE kompatibel, die es Entwicklern ermöglicht, schnell und einfach Anwendungen zu programmieren. Es unterstützt auch andere Entwicklungstools wie CircuitPython und Zephyr.
- Abmessungen: Das Board hat eine Größe von 45 x 18 mm und wiegt nur 5 g, was es sehr kompakt und tragbar macht.
Ausführliche Spezifikation
Arduino Nano 33 BLE (Sense) — Zephyr Project Documentation
Konfiguration
Arduino Nano 33 BLE — PlatformIO latest documentation
Konfiguration Video
Nano33 BLE Sense – Download and Flash Knowledge Pack – YouTube
onsemi RSL10-SENSE-GEVK Platform
Die ON Semiconductor RSL10-SENSE-GEVK-Plattform ist ein Entwicklungs-Kit für Rapid Prototyping und Proof-of-Concept von IoT-Anwendungen, das auf dem RSL10-Bluetooth-Low-Energy-System-on-Chip (SoC) von ON Semiconductor basiert. Das Kit enthält einen Sensor-Hub und eine Vielzahl von Sensoren wie Beschleunigungsmesser, Gyroskop, Magnetometer, Luftfeuchtigkeitssensor, Temperatursensor und Umgebungslichtsensor.
- Sensoren: Die RSL10-SENSE-GEVK Platform ist mit einer Vielzahl von Sensoren ausgestattet, darunter Beschleunigungsmesser, Gyroskop, Magnetometer, Umgebungslichtsensor, Luftdrucksensor und Temperatursensor.
- Prozessor: Das Board ist mit einem onsemi RSL10-Mikrocontroller ausgestattet, der eine extrem geringe Stromaufnahme von nur 62,5 nA im Sleep-Modus aufweist.
- Konnektivität: Die Plattform unterstützt Bluetooth Low Energy (BLE) 5.0, um eine drahtlose Verbindung zu anderen Geräten und Cloud-Plattformen herzustellen.
- Stromversorgung: Das Board kann über eine USB-Verbindung oder eine externe Batterie betrieben werden.
- Entwicklungssoftware: Die RSL10-SENSE-GEVK Platform wird mit der onsemi IoT Development Kit (IDK) Software geliefert, die eine einfache Entwicklung von IoT-Anwendungen unterstützt. Es ist auch mit anderen Entwicklungstools wie Arm Mbed OS und Zephyr kompatibel.
- Abmessungen: Das Board hat eine Größe von 36,5 x 29,5 mm und wiegt nur 4 g, was es sehr kompakt und tragbar macht.
Anleitung
SensiML | onsemi
Beispiel-Video
https://www.youtube.com/watch?v=hVGfhvcoe6E
Weiterführende Informationen
Homepage
SensiML – Making Sensor Data Sensible
SensiML Videos
SensiML – YouTube
SensiML Analytics Toolkit – Quick Starter Tutorial
SensiML Analytics Toolkit – Quick Start Tutorial Chapter 1 – YouTube
Noch mehr Informationen zu den Themen IoT, AIoT und KI finden Sie auf den Seiten unserer IoT Manufaktur.